不积跬步,无以至千里;不积小流,无以成江海。
大家好,我是闲鹤,微信:xxh_1459,十多年开发、架构经验,先后在华为、迅雷服役过,也在高校从事教学3年;目前已创业了7年多,主要从事物联网/车联网相关领域和业务。
喜欢交友、骑行、写毛笔字、弹吉他、玩硬件和写代码。
导读
很不经意之间,从事车联网开发已将近6年多,这一路走过来,物联网终端数由原来的几万,到目前的近100万;框架经历了好几次的重构和调整,到目前基本处于稳定状态;近期我会总结这几年在工作、技术、框架、管理等方面的一些个人理解,一方面是自己的一些深度思考、反思,另一方面可以和大家进行沟通和学习。
万丈高楼平地起,架构框架先跃出。
我大致整理了一个提纲,这篇我主要描述物联网/车联网架构,只有架构清晰了,你所要承载的终端数和业务逻辑,以及未来的扩展,就相对容易了。
行业需求分析
在做任何事之前,先要弄清楚这个事的需求是什么,这个事的特点什么,欲达到什么效果,未来几年后可能的方向(扩展性)。所以在首次接触这个项目的时候,就花了比较多的时间做调研。
需求:实现将车联网终端设备进行入网,可以进行远程监控和控制。
特点:
- 终端与物联网平台通讯方式 TCP 长链接,需维护和检测与终端的心跳。
- 传输数据量大而频繁:终端会每隔1-2秒(静止30秒)上报终端的经纬度、报警事件数据、电池数据(电压、电流、温度等BMS数据)。
- 终端设备的增长:终端设备的增长取决是市场能力,市场能力强的话,增长就快。
- 能同时支持多种协议:不同厂家有自己的协议,而且还能支持不同设备。所以协议有不同的传输形式,比如,有文本协议,有二进制协议,也有不同的数据格式。
效果:系统的稳定性。系统是否稳定直接关系到用户的体验,以及直接影响到产品在市场中的竞争力,所以稳定是物联网系统的基石。
稳定的表现:
- 能随时的进行查看设备状态,和远程控制设备。
- 当设备数量达到一定量后,能很方便的进行横向扩展。
简而言之,就是系统能快速的处理数据和能快速、方便的进行横向扩展。
系统架构
需求和目标确定后,就是框架的设计了,如下面框架图: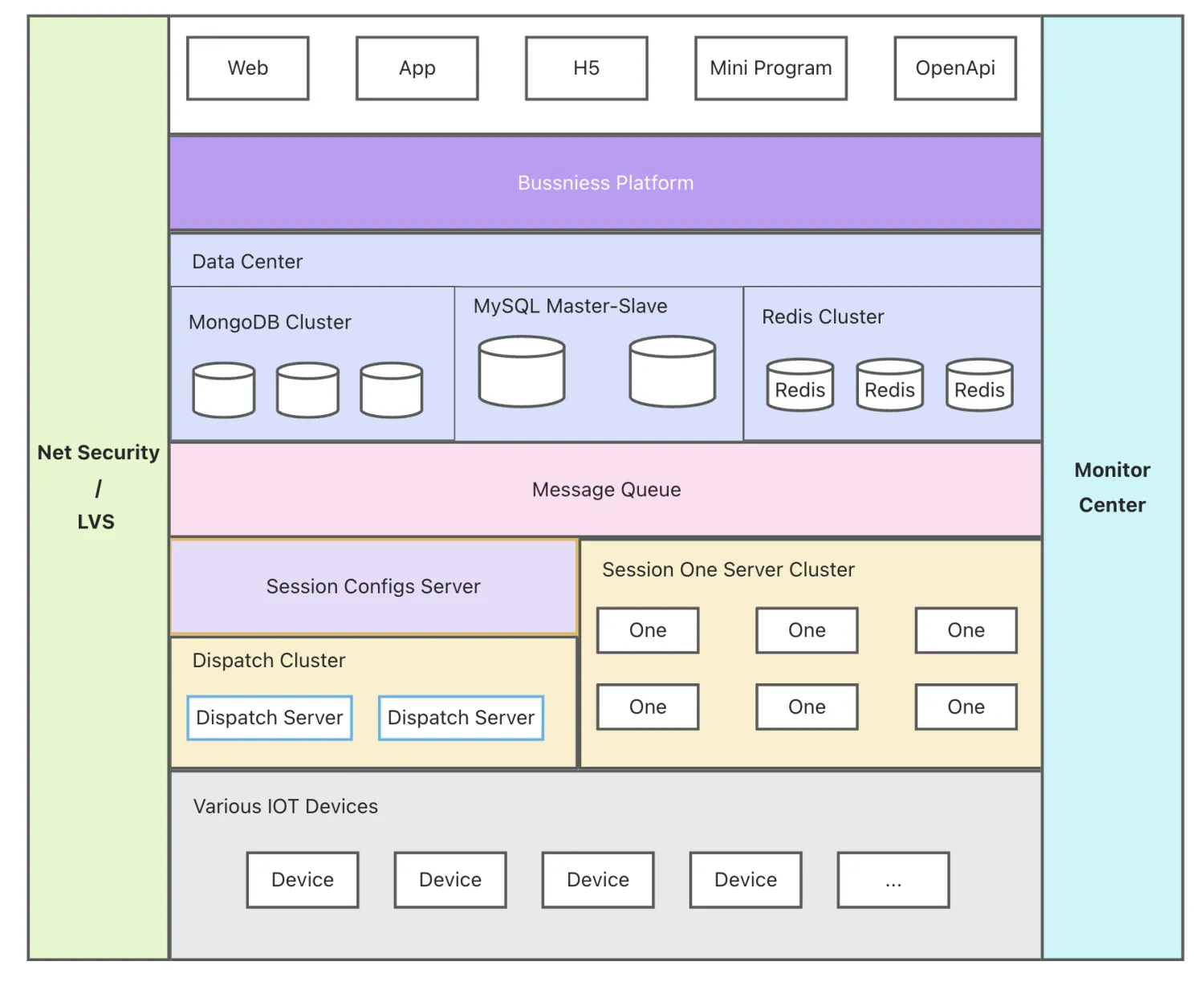
因为之前在华为和迅雷工作时,主要是做高并发网络框架搭建工作,负责华为无线终端和迅雷用户的网络接入,同时在教学的3年空闲时间内,阅读了大量的TCP/IP协议族等相关理论书籍并把书籍中的理论尽量进行了代码的实践(相关文章可参考往期文章),所以在设计物联网框架时,之前的一些工作经验恰好就起到作用了。
这套物联网系统,当时我取名为 One ,寓意为:
- One,一,道生一,一生二,二生三,三生万物;人、作者、念头、想法、市场谓之
道,One谓之起始之源;繁华的未来从One开始。 - One,谐音
万,万物之始、万物连接,One 连接所有的 IOT 终端设备,通过互联网赋予 IOT 设备智能的意义。
每一层都是一个分布式聚群,都能横向扩展。
- Session Configs Server:他在整个的 One 服务中起着
注册-发现的作用:- 每一个活跃的 One 都会向他进行服务注册,每一个无法服务的 One 都会剔除配置群;
- 为 Dispatch 提供了活跃 One 的数据
- Dispatch Server:根据 Session Configs Server 的数据,返回给 Device 合适的 One Server。
Session Configs Server 和 Dispatch Server 共同构建了类似 nginx 的负载均衡功能。
- One Server: 负责与 Device 进行通讯,TCP 长链。可以是一个分布式群,每一个单体服务都是相对独立的,可以动态的进行增加和剔除,不需要做任何的配置。One Server 对 Device 提交的数据根据协议进行解析,对下行的数据进行封包下发。
- Message Queue:消息队列,对 One 上行数据与存储进行异步隔离,将数据的解析和存储进行解耦。
- Data Center:数据存储这块,目前我们根据数据的使用场景、紧急程度,使用了不同的存储方案,比如:MySQL、MongoDB、Redis 等
- Business Sever:负责业务处理
- 业务层的LVS,期初是用nginx实现的,后期接触到了阿里云的 SLB,就转用了阿里云的 SLB。
- Monitor Center:是对所有服务异常的监控,这类监控包含:
- 服务器硬件资源的监控:内存、CPU、磁盘、负载等
- 每个服务节点的监控:One、Redis、MySQL、RabbitMQ、MongoDB、业务服务的异常日志分析 等
监控服务收到异常数据后,立马通过微信公众号把告警通知给相关负责人。
各层的数据流如下图: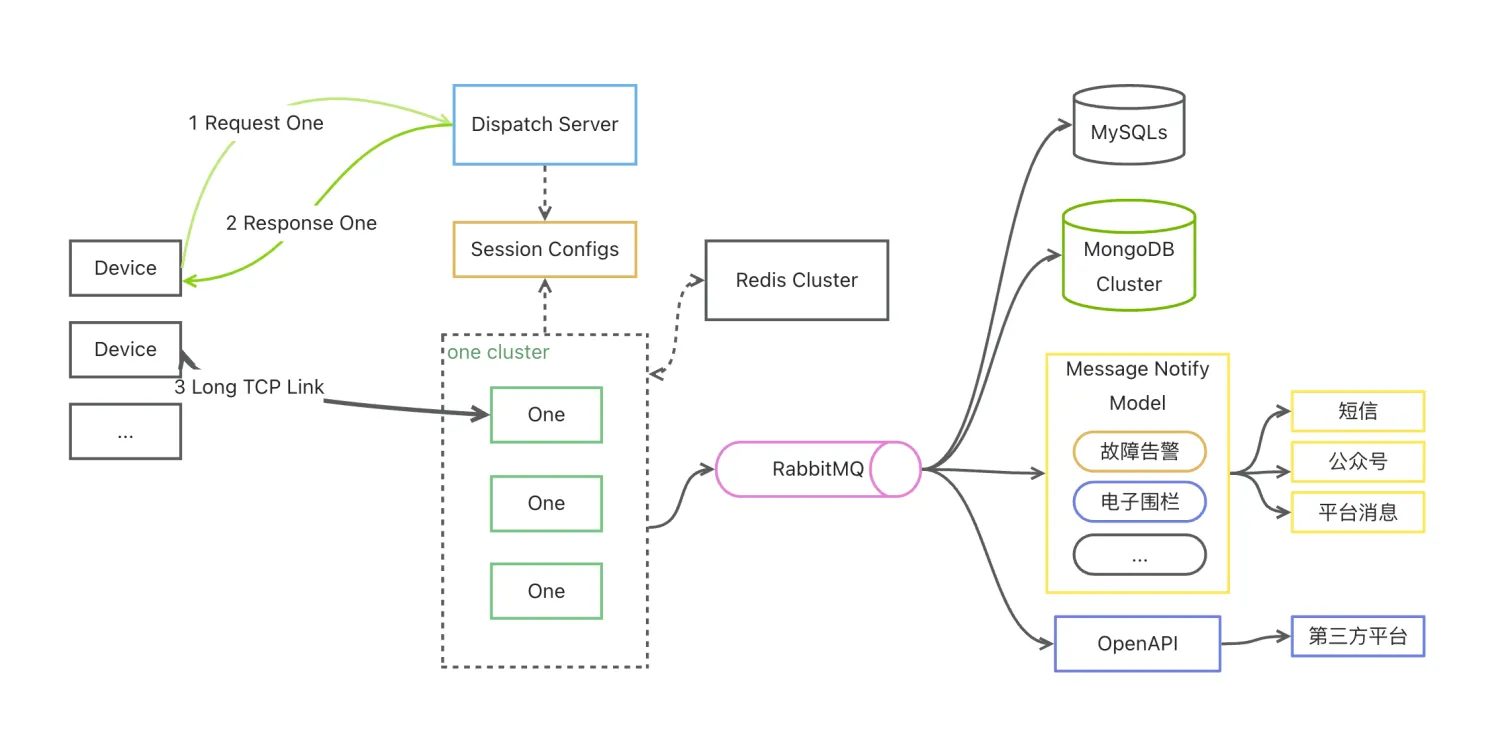
上面的框架图和数据流图都是包含有集群、多实体的,单实体的One如下: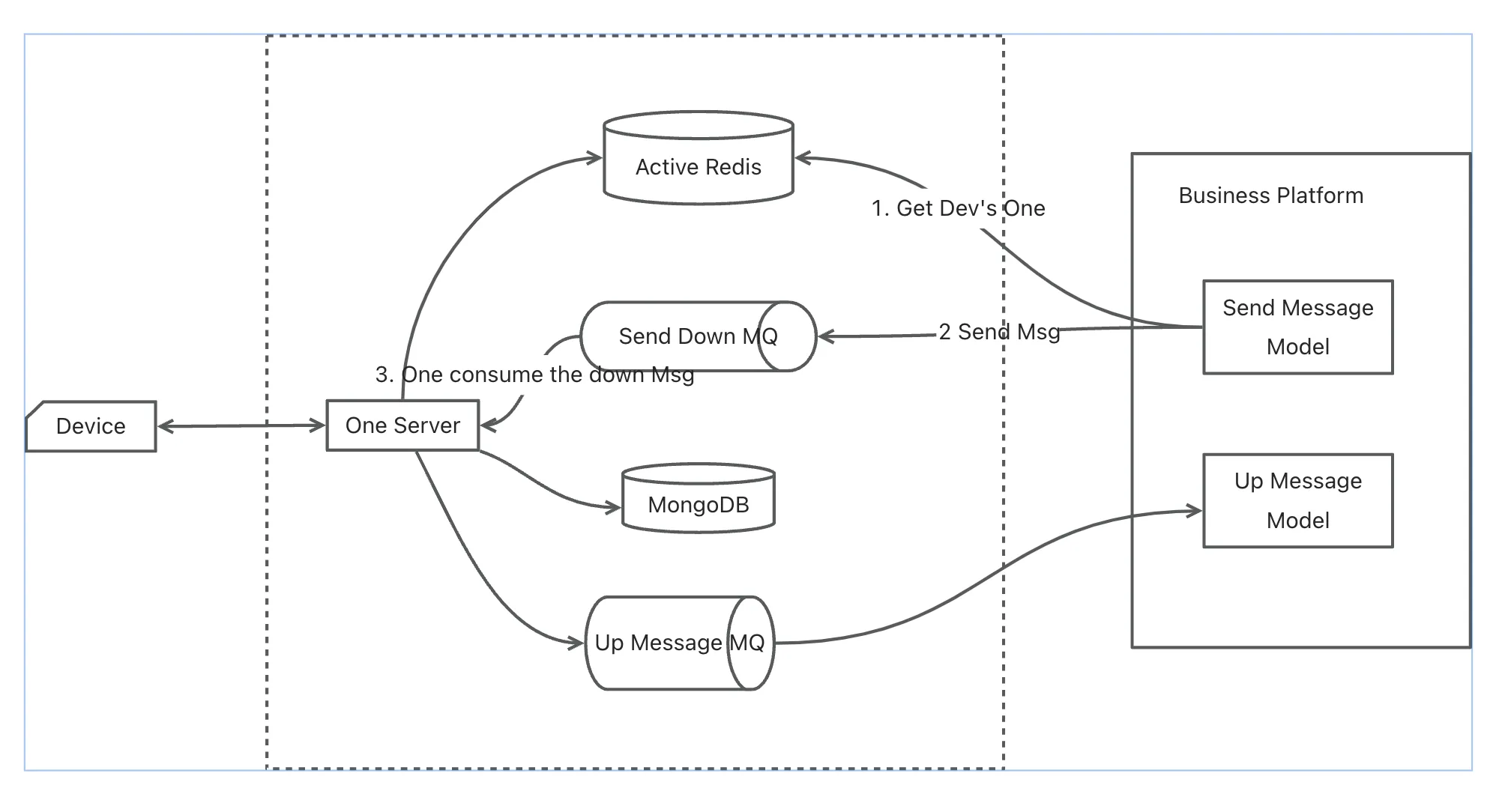
在设计这套框架,以及在框架的前期实践时,有这么几个难点:
- 单机接入设备上限,如果达到了单机的上限,如何进行无感的增加新机器。
- 高峰期的流量相当的大,在成本有限的情况下,如何处理高峰期的流量。
- 数据的处理与 One Server 如何解耦。因为一旦数据量大、并发高的情况下,数据的落盘处理耗时是远远大于数据的接入的,如果是同步执行的话,One Server 必定会导致被“拖死”。
- 大数据的存储,我们目前同时在线的设备终端有30w,一天产生的数据有2T,如何对这些大数据进行存储和读取在当时也是一个非常头痛的问题。相关内容可看往期文章:
以上问题在大的方向上得以解决的话,基本上能在百万级别的IOT设备接入是没问题的,数据存储能处理好的话,基本就是可以做到横向扩展,通过增加机器的方式来支持接入更多的IOT设备了。
至此,这篇文章就结束了,如有想再深度了解的,欢迎进行留言沟通。
相关阅读:
不积跬步,无以至千里;不积小流,无以成江海。
大家好,我是闲鹤,微信:xxh_1459,十多年开发、架构经验,先后在华为、迅雷服役过,也在高校从事教学3年;目前已创业了7年多,主要从事物联网/车联网相关领域和业务。
喜欢交友、骑行、写毛笔字、弹吉他、玩硬件和写代码。
个人博客: https://blog.uwenya.cc/
CSDN:https://blog.csdn.net/xiongxianhe
微信公众号: