背景
- 行业: 车联网
- 机器配置:阿里云服务 8核 16G内存 3M带宽 阿里云操作系统
- 单台server接入设备:5w
- 终端产品:GPS定位设备
- 终端与平台通信方式:TCP长链
前言
近期服务器每到高峰的时候,就会有很多的处理不过来的任务队列被积累,这种任务长期被积累的话,不能及时响应终端时,终端任务无法链接,就又重新发起TCP链接,这将导致恶性循环,最后服务器会被拖垮,也无法与终端进行通信。
解决方案
在不改变现有服务器硬件环境下、代码相对改动比较少,同时能允许部分数据丢弃的情况下,使用“泄峰”方法来处理在高峰期,无法正常响应终端的问题。
泄峰
- 使用规则:
- 在保证设备能链接,能正常下发指令到终点
- 允许部分数据被丢弃
- 泄峰策略:
- 丢弃哪些数据?
- 丢弃频率?
丢弃哪些数据
丢弃哪些不主要影响业务的数据,且这些数据的交互非常频繁。以我们现有的数据来说,主要有3大类数据比较频繁:
- 心跳数据
- 定位数据
- 透传数据
针对以上分析,对每类数据进行单独控制,根据实际情况进行单独泄峰,同时记录丢弃的数量,以便进行统计参考。
丢弃频率
丢弃频率,可根据业务进行调整,可在高峰期手动执行脚本泄峰,也可以使用crontab进行每隔多少分钟进行,或自己写频率脚本。
目前,我采用的配置是,泄峰时长为2分钟,每3分钟进行泄峰。
泄峰结果
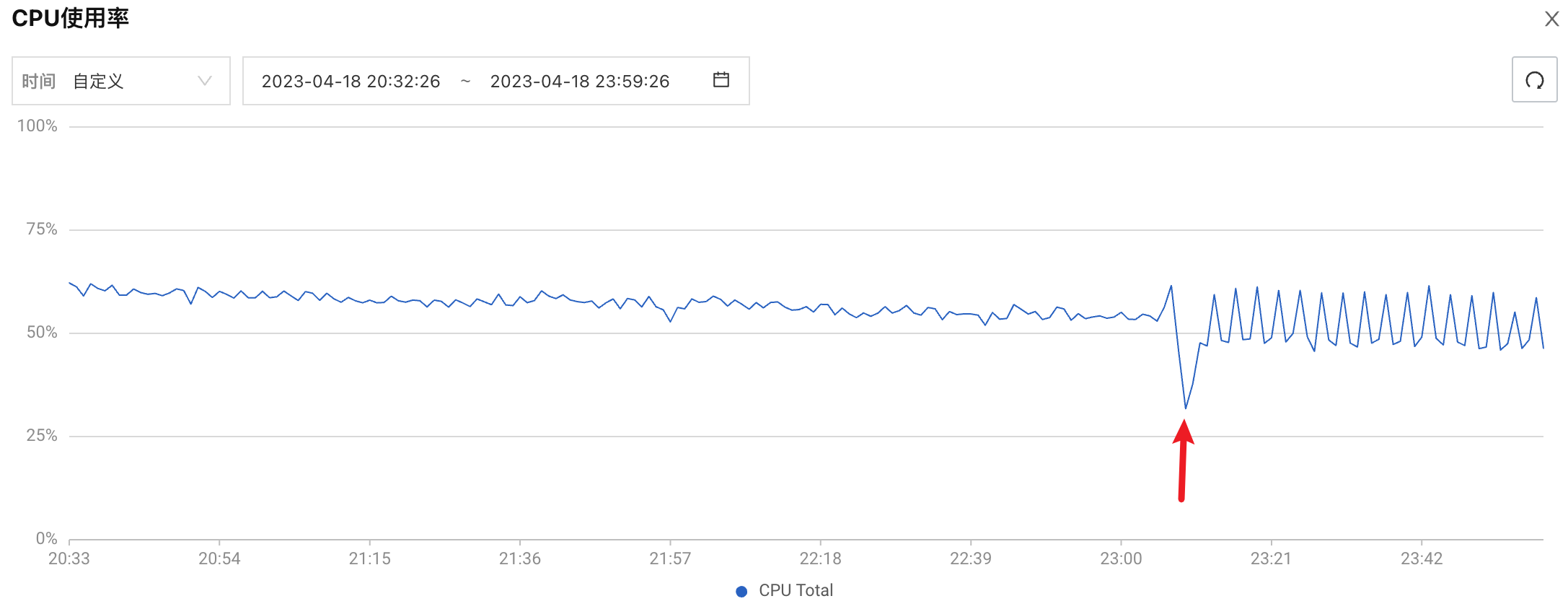
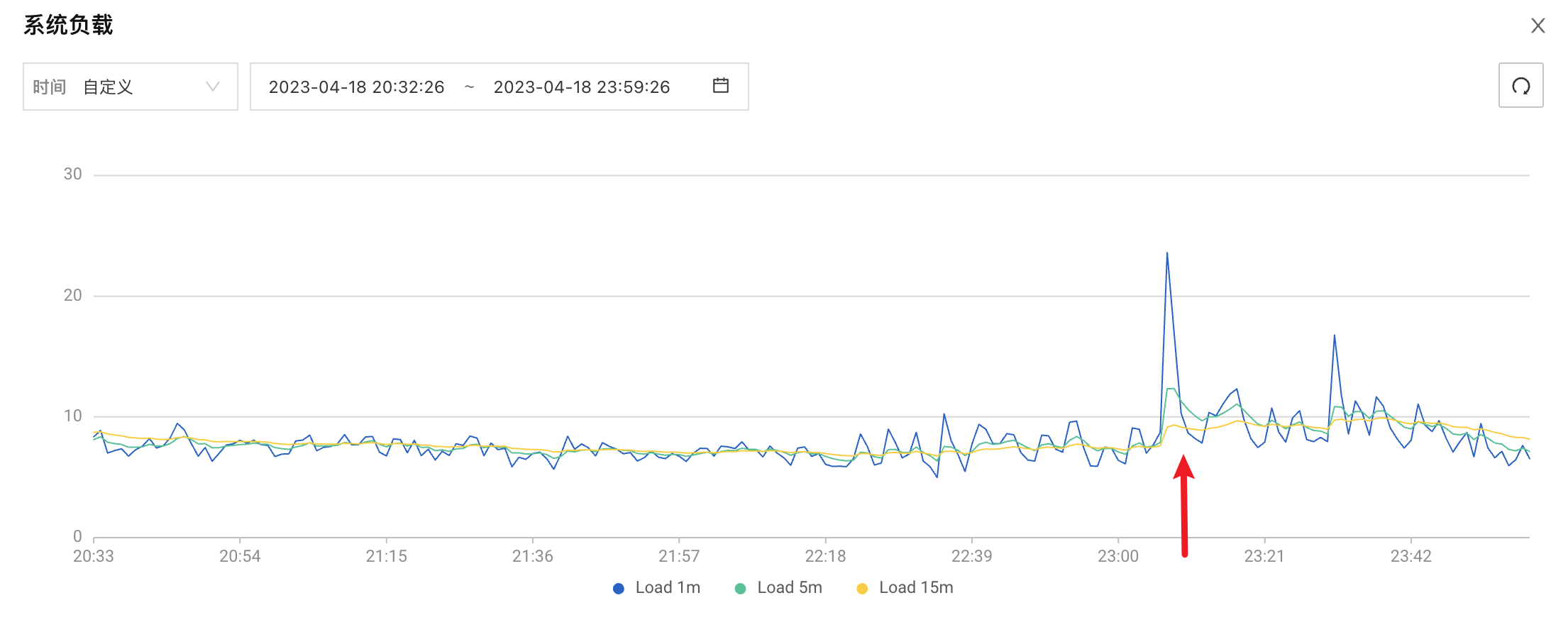
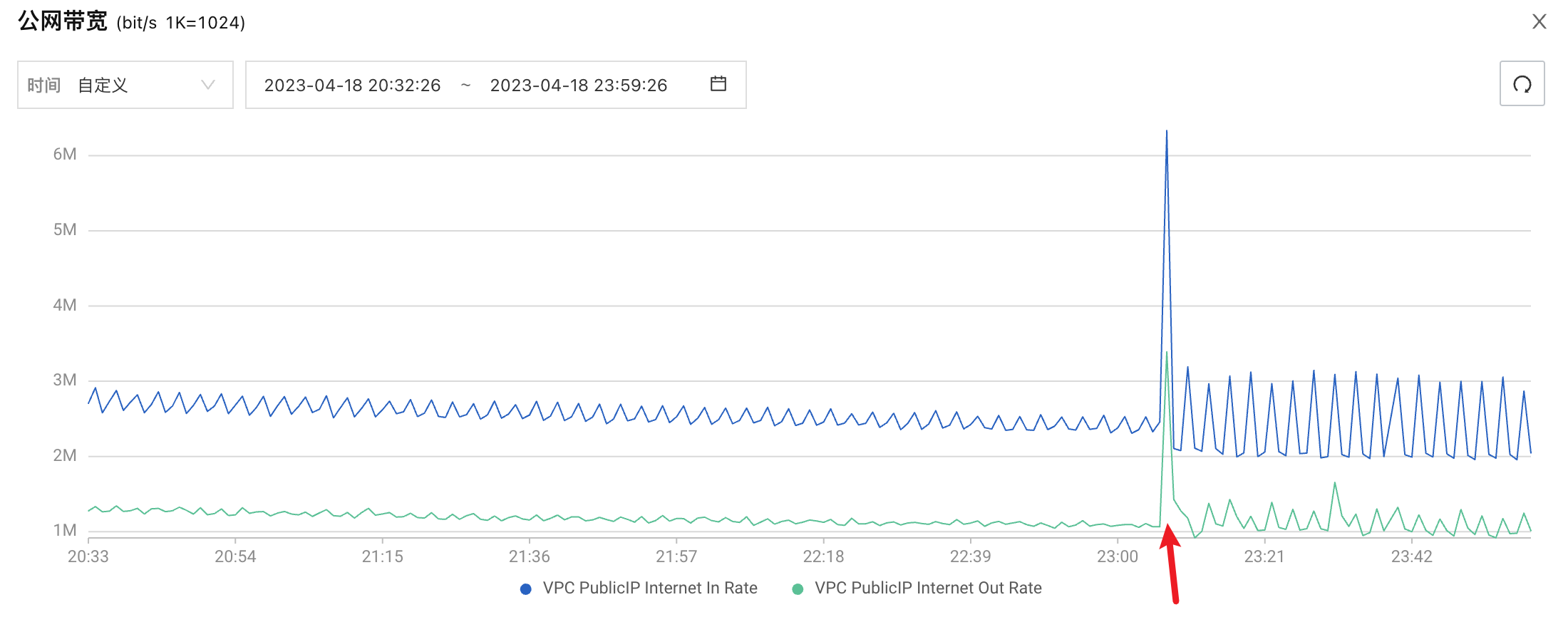
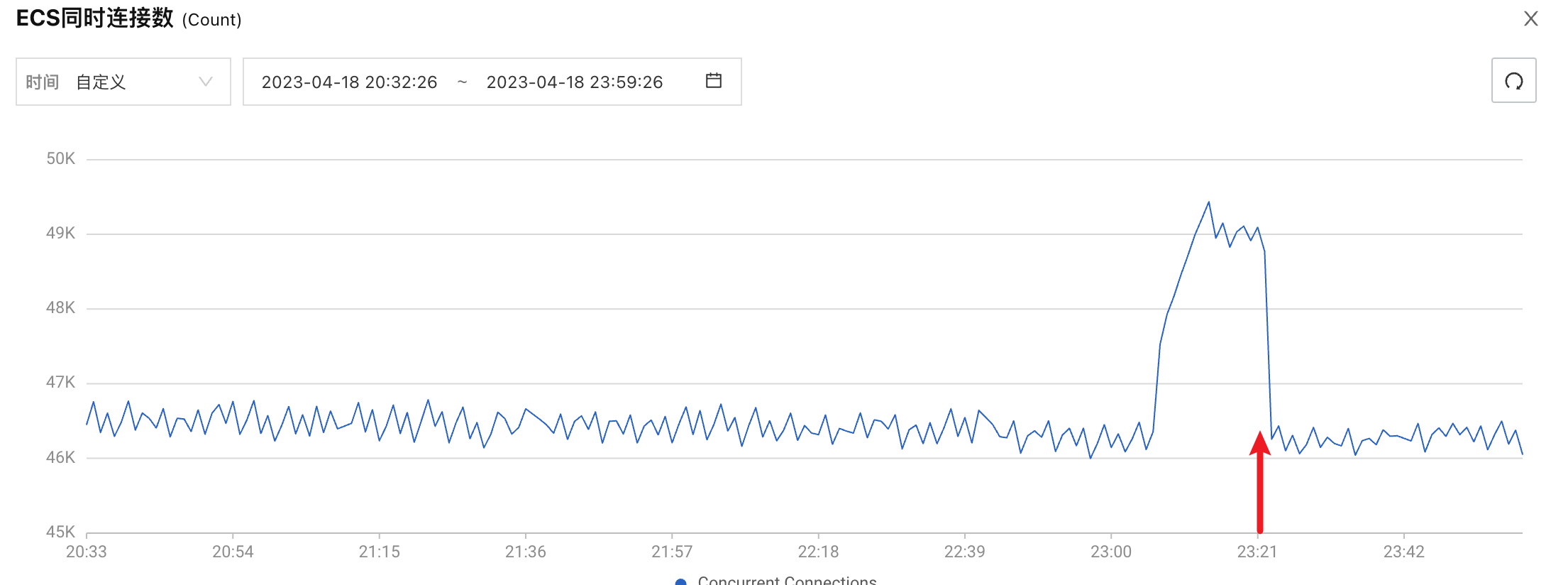
总结
泄峰的主要目的是,在高峰期,为了服务能正常稳定的运行,而采取的丢弃一部分数据的策略。具体的使用可根据自身的业务场景进行。
代码示例
泄峰配置:
return [
'HEART_HY' => 120, // 单位秒
'HEART_JT' => 120, // 单位秒
'LOCATION_HY' => 120, // 单位秒
'LOCATION_JT' => 120, // 单位秒
'BMS_HY' => 120, // 单位秒
'BMS_JT' => 120, // 单位秒
];泄愤控制:
/**
* 获取泄峰值, 如果是要泄峰,同时记录泄峰次数
* @param $modul: 要泄峰的模块: HEART LOCATION BMS
* @return bool: true: 泄峰 false: 不泄峰
* @throws \RedisException
*/
public static function getLeakPeakValue($modul) {
$pool = self::getAliveRedisPoolInstance();
$redisInstance = $pool->get();
$key = "LEAK_PEAK_VALUE_$modul";
$value = $redisInstance->get($key);
if(!empty($value)) {
$inc_key = "${key}_inc_" . date("Y-m-d");
$redisInstance->incr($inc_key);
$redisInstance->expire($inc_key, 86400);
}
$pool->put($redisInstance);
return !empty($value);
}
/**
* 设置泄峰值
* @param $value
* @param $ex
* @return void
* @throws \RedisException
*/
public static function setLeakPeakValue($modul, $ex) {
$pool = self::getAliveRedisPoolInstance();
$redisInstance = $pool->get();
$key = "LEAK_PEAK_VALUE_$modul";
$redisInstance->set($key, 1, $ex);
$pool->put($redisInstance);
}注册ChatGPT账号
微信公众号:
本文为原创内容,作者:闲鹤,原文链接:https://blog.uwenya.cc/1275.html,转载请注明出处。